Software Concept
This section is aimed at users who are looking to gain an understanding of the full concept and ecosystem of HH Data Management. Understanding this will enable users to take advantage of all the features of HH Data Management to customize the software and end up with a system that meets their requirements. HH Data Management is designed to be flexible to support various working concepts within organisations in different motorsport disciplines.
One of the main goals for HH Data Management is to store all engineering data for a motorsport organisation and create relationships between different sets of data to make analysis easier and more efficient. One example of this is being able to access setup data while analysing logged data in the same software, without having to copy constants between different software environments.
System Architecture
There are various parts of HH Data Management that should be understood to know how the whole system works.
Offline Synchronization
HH Data Management is built on top of an offline-first syncing framework. This means that the basic features of the software are fully functional while not connected to the server. All data is stored in a database on the local computer. Any changes made while offline are stored locally and sent to the server automatically when the internet connection is restored. Although the goal of the software is to make the syncing framework invisible to the user there are sometimes where this is not the case. For example, when the software is first launched, the user needs to wait for the initial data set to download. Then to access any event data it is necessary to subscribe to the event and this will download the data to the local database.
The syncing framework works by sending any changes made locally to the server in the form of sync operations. An example of a sync operation might be an update setup sync operation when a setup parameter is changed. This sync operation will contain the information to know what setup was changed and what change was made.
Server
The HH DM server runs in the cloud and is the central point of the system. The server is backed by the main database that stores all the data and is the single source of truth. All sync operations must travel to the server before it can be persisted into the server database. When a client sends a sync operation to the server, the server process it, persists the information into the server database and then sends that same sync operation to all other clients that belong to the source account who are currently connected to the server so that they receive the update soon after the original change was made.
Client
The HH DM client software is installed on a local user's computer, and allows the user to fully interact with the data. The client has a local database where data is stored and all changes made on the client must go through this client database.
API
The API runs on the server and generally supports all operations that can be carried out in the client. The API can be used to programmatically interact with the HH DM server.
Cloud integrations
HH Data Management can be connected to send data to external applications either by putting these serialized messages in a user specified AWS SQS queue or by sending the message as an HTTP callback. Combined with the API, these callbacks give the option to fully integrate HH DM into any external workflows.
Attached files
For storing larger chunks of data that cannot be stored in a database (such as logged data or photos), files can be attached to all elements in the software (setups, runs, laps, etc.). These attached files are similar in concept to email attachments. After the files are attached they will be uploaded to the server, and once they are available on the server they can be downloaded by all other users on the account. Files can optionally be set to automatically download on all users computers. If the file doesn't automatically download then users can choose to download it if they need access to it.
Lap KPIs
If logged data is attached to a run in HH Data Management then there is an option for HH Data Management to automatically process this file and calculate lap KPIs (key performance indicators). This calculation is performed on the server, so the attached files must finish uploading before they can be processed. The mathematical expressions for these KPIs can be fully defined in the software using a simple programming language. After the KPIs are calculated the results are written back to the database and available to all clients. This makes it easy to review the KPIs from past seasons and races easily as all the data is stored in the database. The advantage of processing the files on the server in such a manner is that it makes it easy to reprocess old datasets as more KPIs are added.
Website
After logging into hh-dev.com a web management portal is available to perform various admin tasks, like managing users, setting up permissions and definition integrations. Furthermore the latest version of the software can be downloaded from this website.
DMI
The DMI (Data Management Integration) is a plugin for HH Timing that is used automatically send timing data to HH Data Management. The DMI also has the ability to read telemetry data to write end of lap values to HH Data Management also.
Data Model
The software has a basic data schema that is designed to cover the requirements of most organizations. The higher level data is organized with championships → events → sessions. In an event there are setups, runs, run plans etc. The schema allows data to be stored in the most appropriate location and then access it wherever needed in the software. For example, if there is a specific BOP parameter that changes per event then this could be stored in the event. Then this value can be accessed from the setup or lap in a math parameter if its needed for a certain calculation. The following diagram shows the full data model of HH Data Management.
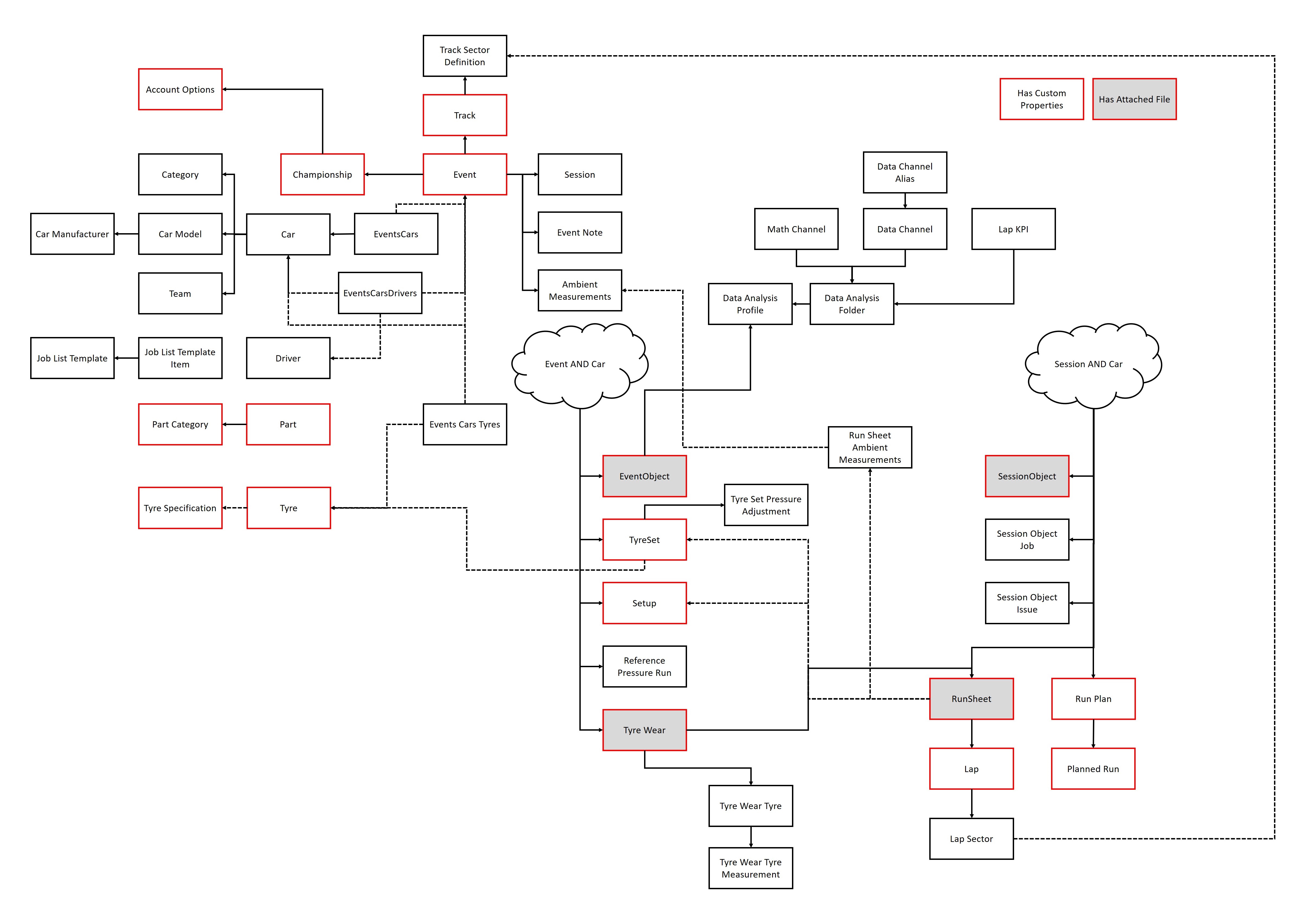
To simplify this explanation, the diagram is looked at in four separate parts:
- Management entities
- Event entities
- Event/Car entities
- Event/Car/Session entities
Management Entities
Management entities are considered to be all data entities that do not correspond to a specific event, or are related to the configuration of the software, such as championships, tracks, drivers, cars and events and sessions.
Event Entities
Event entities are considered to be all data entities that belong to a specific event. A weather measurement at an event would be considered an event data entity.
Event/Car Entities
Within the event entities there are event/car entities which are items like tyre sets or setups. They belong to a specific car in an event.
Event/Car/Session Entities
Within the event/car entities there is the event/car/session entities which are items like run sheets, which belong to a specific session and car in an event.
Definitions
The concept of definitions in the software is the basis of all user customization of data in the software. Each entity in the pre-defined software schema has an associated definition. These definitions can be customized by users. A user is able to define simple and complex custom parameters on all data entities in the software. The definitions are customized in the Custom Property Definitions view. The following types of parameters exist:
- Parameters
- Math Parameters
- Part Parameters
- Assembly Parameters
- Collections
- Attached Files
Parameters
Parameters are simple scalar values. Each parameter has a static type of numeric, text, boolean (true/false) or date/time. If the value is numeric some additional properties can be entered for the parameter such as dimension/unit. Parameters are used to store simple scalar values like a corner weight in a setup.
Math Parameters
Math parameters allow users to type math expressions to calculate new values. For example, if the setup has four corner weights then a math expression could be used to calculate the weight distribution and show this on the setup sheet.
Part Parameters
Part parameters allow the user to define a parameter that will be linked to a part. The linked part category must be defined when creating a part parameter. Part parameters are used to store a reference to an object based on a drop down menu. For example, if there is a set of springs that can be chosen in a setup, then a part parameter could be used to store the spring that is used in each setup.
Collections
Collections allow the user to define an array of objects linked to the current object. When adding a collection to a definition the collection item definition must be specified. This is the definition that determines the structure of each item in the collection. Collections are used to store arrays of data, some use cases are:
- On a bump rubber part a look up table could be created to define the stiffness of each component. This could be represented using a collection where each collection item is a date point in the look up.
- On the EventCarData object a collection of measurements could be created to recorded each time the car passes through scrutineering. In this case each collection item would represent a trip to scrutineering and the collection item definition parameters would represent each possible measurement that could be taken during scrutineering.
When creating definitions and deciding where to define the parameters keep in mind that this is the data model, which is completely independent of the user interface of the software. Parameters should be created on entities where it makes the most sense to store the information. If this information is needed elsewhere in the software, it can be retrieved with a math expression, and shown in the user interface using the various user interface customization features available in the software. Do not let user interface considerations influence the design of the data model.
User Interface Customization
There are a number of ways to customize the user interface in the HH Data Management client. The two main approaches are:
- within the software
- using a plugin
Within the software, tables in the existing views can be customized, and entirely new custom views can be created. All of these user interface customizations will involve deciding what the user interface should look like and then linking each element to parameters on the relevant definitions.
Plugins
When the customizations available in the software are not powerful enough to meet a customer's needs, a plugin can be created. A plugin consists of additional code that is loaded into the software while it is running. There are a number of access points built into the plugin framework that allow existing behaviour to be adjusted, for example the run plan calculator can be customized to work for either gasoline or electric cars. On the other hand entire new displays can also be written in a plugin - any view already in HH Data Management can in theory be recreating entirely in a plugin.